
Moonshot AI, a Beijing-based startup, has released its Kimi K1.5 model, which has reportedly outperformed major AI players such as OpenAI’s GPT-4o and Claude Sonnet 3.5 on multiple key benchmarks.
The Kimi K1.5 model has been touted as a game-changer in the AI industry, positioning China as a rising competitor in the AI arms race.
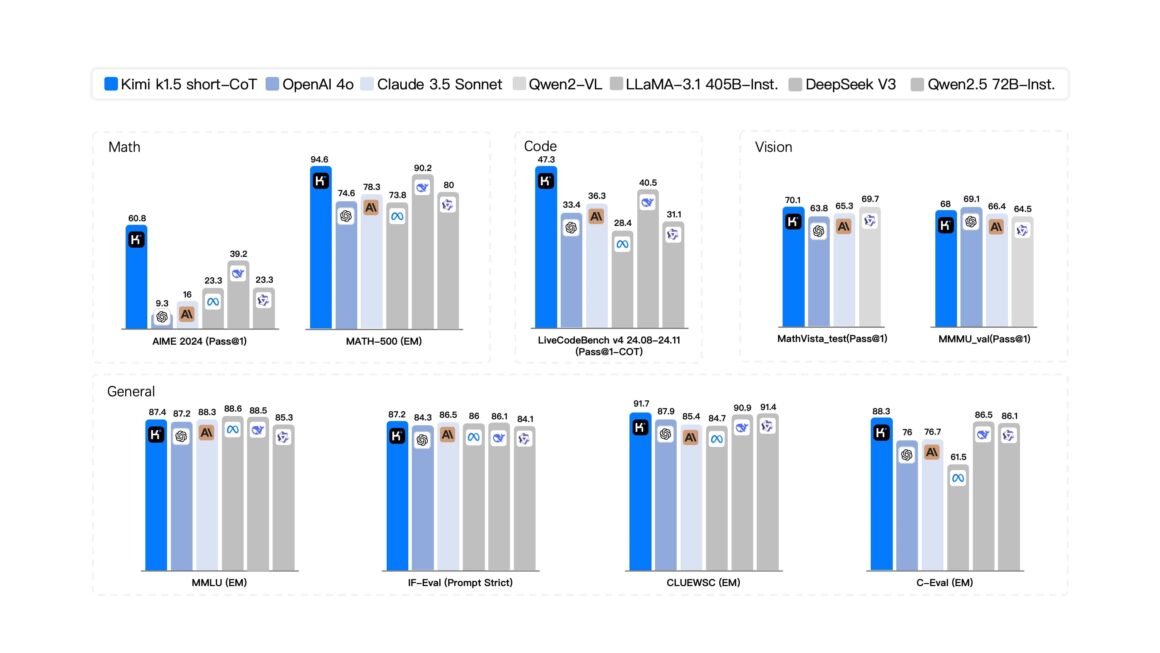
Performance Metrics: Kimi K1.5 Takes the Lead
The Kimi K1.5 has scored 96.2 on the MATH 500 benchmark, surpassing GPT-4o, and performed at the 94th percentile on Codeforces, excelling in coding and reasoning.
It is particularly noted for its ability to combine text, images, and code, making it a multimodal model.
This capability allows Kimi to handle tasks that involve visual data alongside textual inputs, a significant advantage over its competitors.
Innovative Approach: Reinforcement Learning and Multimodal Reasoning
Kimi’s strength lies in its use of reinforcement learning (RL), allowing it to learn through exploration and reward-based systems, unlike traditional models that rely on static datasets.
This enables Kimi to improve its problem-solving and reasoning abilities, particularly in complex mathematics and long-context tasks, such as handling up to 128k tokens in text.
Competitive Edge and Efficiency
Built at a fraction of the cost of models like GPT-4, Kimi K1.5 demonstrates efficiency and versatility in various domains, from mathematical problem solving to AI-generated code.
It is seen as a direct challenge to the US-dominated AI landscape, particularly in the wake of DeepSeek-R1‘s rise in popularity.
This shift marks a pivotal moment in AI development, with Kimi K1.5 positioning itself as a formidable competitor to global leaders in the field.